Topic 1.3.1 – Inserting Data Manually Using .CSV Import
You can import any data into the history blocks as long as the data is formatted according to a specific comma-separated values (CSV) format. The file should be then copied into a special folder on the Historian Server computer.
If you are inserting or updating values that have a time period spanning across or included in a current gap in the history blocks, a new block can optionally be created to patch the gap and hold the insert/update.
Configuring CSV File Import Folders
By default, the import folders are created in the main Historian Server data folder when the product is installed. For example, if you specified D:\Historian\DATA\Circular as the circular data folder, the CSV data import folder is D:\Historian\DATA\DataImport.
You can modify the location of the data import folder by modifying the value of the DataImportPath system parameter. The different import folders are described as follows:
- \DataImport – Used for normal CSV import files
- \FastLoad – Used for fast load CSV import files. Files in this folder are processed one at a time, in the order that they appear in Windows Explorer as you are viewing the folder contents.
- \Manual – Used by classic storage
About Normal CSV File Imports
Use the normal import mechanism if you primarily want to modify a small amount of existing data stored in Historian Server or store a small amount of new values. The insert of an entire CSV file results in a single new version of the data. If an inserted data point falls exactly on an existing timestamp, the data value is added to history and the existing data is maintained in history.
For a normal CSV import, the CSV file format and the format of the data contained within the file is very flexible. However, this flexibility requires the system to perform a large amount of processing on the data before it can be imported. Thus, there is an inverse relationship between amount of data to process and import speed. The time required to process a file is at least exponentially related to the number of values contained in the file.
Additional considerations for a normal import are:
- If multiple files are to be processed at the same time, the total size of the CSV file is limited to less than 4 MB.
- The CSV file cannot contain more than 100,000 data values.
- The number of tags represented in the file cannot exceed 1024.
- Single files of up to 6 MB will be processed, provided that they do not exceed the file data and tag limits.
About Fast Load CSV File Imports
Using the fast load CSV import mechanism, you can import original data very quickly, using essentially the same CSV file format as for a normal import, with some modifications.
A fast load import is much faster than a normal CSV import. Also, there are no restrictions on the size of the file to import, or the number of tags or data values in the file.
However, the data that is contained in the CSV file for a fast load import must be formatted in time sequential order. It is this ordering that allows the system to process a fast load CSV file more quickly than a normal CSV file.
Put a formatted CSV file into a special \FastLoad import folder. A fast load import can only be applied where there is no existing stored data. Fast load importing is intended for manual tags that do not have data. They are not suitable for routine data acquisition.
Generally, use the fast load import if
- It is not is not feasible to perform a normal CSV import.
- You need to import very large CSV files.
- You want storage rules applied to the data you are importing. A normal CSV import does not apply storage rules; everything is stored as a delta.
The following is an example of an insert of data values for a single tag. The pipe ( | ) is used as a delimiter:
Configuring CSV File Import Folders
By default, the import folders are created in the main Historian Server data folder when the product is installed. For example, if you specified D:\Historian\DATA\Circular as the circular data folder, the CSV data import folder is D:\Historian\DATA\DataImport.
You can modify the location of the data import folder by modifying the value of the DataImportPath system parameter. The different import folders are described as follows:
- \DataImport – Used for normal CSV import files
- \FastLoad – Used for fast load CSV import files. Files in this folder are processed one at a time, in the order that they appear in Windows Explorer as you are viewing the folder contents.
- \Manual – Used by classic storage
About Normal CSV File Imports
Use the normal import mechanism if you primarily want to modify a small amount of existing data stored in Historian Server or store a small amount of new values. The insert of an entire CSV file results in a single new version of the data. If an inserted data point falls exactly on an existing timestamp, the data value is added to history and the existing data is maintained in history.
For a normal CSV import, the CSV file format and the format of the data contained within the file is very flexible. However, this flexibility requires the system to perform a large amount of processing on the data before it can be imported. Thus, there is an inverse relationship between amount of data to process and import speed. The time required to process a file is at least exponentially related to the number of values contained in the file.
Additional considerations for a normal import are:
- If multiple files are to be processed at the same time, the total size of the CSV file is limited to less than 4 MB.
- The CSV file cannot contain more than 100,000 data values.
- The number of tags represented in the file cannot exceed 1024.
- Single files of up to 6 MB will be processed, provided that they do not exceed the file data and tag limits.
Using the fast load CSV import mechanism, you can import original data very quickly, using essentially the same CSV file format as for a normal import, with some modifications.
Generally, use the fast load import if
- It is not is not feasible to perform a normal CSV import.
- You need to import very large CSV files.
- You want storage rules applied to the data you are importing. A normal CSV import does not apply storage rules; everything is stored as a delta.
The following is an example of an insert of data values for a single tag. The pipe ( | ) is used as a delimiter:
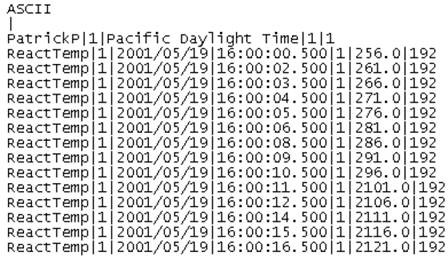
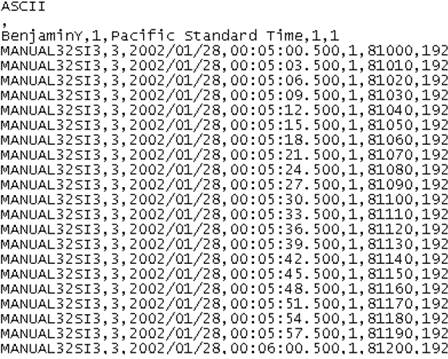
The following is an example of an update of data values for a single Tag. A comma ( , ) is used as a delimiter.

The following is an example of a multipoint update of data values for a single tag. A comma ( , ) is used as a delimiter. The last value is Ignored.
The following is an example of a multipoint update of data values for a single tag. A comma ( , ) is used as a delimiter. The last value is Ignored.
Copying a CSV File into an Import Folder
After you copy one or more CSV files to an import folder, Historian Server attempts to read the file(s) only one time. If the read is successful, the data is automatically converted and merged in with the appropriate history block according to the date range provided in the CSV file. The CSV file is then deleted from the directory. If an error occurs during the import, the CSV file is moved to the \Support folder. A message is also posted in the error log.
Copying a CSV File into an Import Folder
After you copy one or more CSV files to an import folder, Historian Server attempts to read the file(s) only one time. If the read is successful, the data is automatically converted and merged in with the appropriate history block according to the date range provided in the CSV file. The CSV file is then deleted from the directory. If an error occurs during the import, the CSV file is moved to the \Support folder. A message is also posted in the error log.
Last modified: Friday, 21 June 2019, 3:22 PM