Topic 1.4.1 – Advanced Retrieval Modes
This section describes the following retrieval modes:
- Interpolated Retrieval
- Average Retrieval
- Minimum Retrieval
- Maximum Retrieval
- Integral Retrieval
- Slope Retrieval
- Counter Retrieval
- ValueState Retrieval
- RoundTrip Retrieval
About Phantom Cycles
The phantom cycle is the name given to the cycle that leads up to the query start time. It is used to calculate which initial value to return at the query start time for all retrieval modes. Some retrieval modes use the phantom cycle to simply find the last known value prior to the query start time, whereas other retrieval modes use the entire cycle to calculate aggregates. The following table shows the different uses of the phantom cycle:
|
Simple use of phantom cycle |
Cycles not defined, but similar simple use of time before query start time |
Phantom cycle used to calculate aggregates |
|
Cyclic |
Delta |
Min |
|
Interpolated |
Full |
Max |
|
Best Fit |
Slope |
Average |
|
|
|
Integral |
|
|
|
Counter |
|
|
|
ValueState |
|
|
|
RoundTrip |
Interpolated Retrieval
Interpolated retrieval returns interpolated values if there is no actual data point stored at the cycle boundary.
This retrieval mode is useful if you want to retrieve cyclic data for slow-changing tags. For a trend, interpolated retrieval results in a smoother curve instead of a stair-stepped curve.
By default, interpolated retrieval uses the interpolation setting specified for the tag in Historian. This means that if a tag is set to use stair-step interpolation, interpolated retrieval gives the same results as cyclic retrieval.
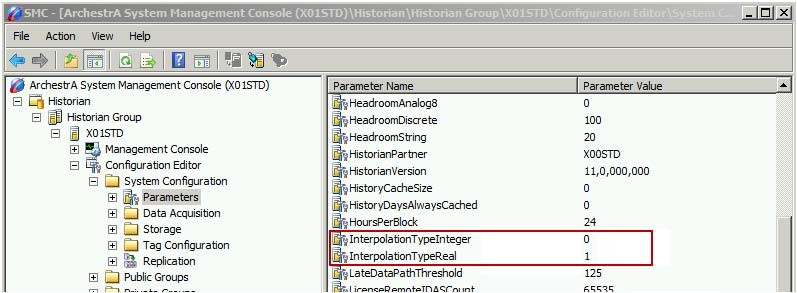
There are two parameters that determine the default tag interpolation.
Interpolated retrieval is a bit slower than cyclic retrieval and it shares the limitations of cyclic retrieval in that it may not accurately represent the stored process data.
Average Retrieval
For the average retrieval mode, a time-weighted average algorithm is used to calculate the value to be returned for each retrieval cycle.
For a statistical average, the actual data values are used to calculate the average. The average is the sum of the data values divided by the number of data values. For the following data values, the statistical average is computed as:
(P1 + P2 + P3 + P4) / 4) = Average
Minimum Retrieval
The minimum value retrieval mode returns the minimum value from the actual data values within a retrieval cycle. If there are no actual data points stored on the historian for a given cycle, nothing is returned. NULL is returned if the cycle contains one or more NULL values.
Maximum Retrieval
The maximum value retrieval mode returns the maximum value from the actual data values within a retrieval cycle. If there are no actual data points stored on the historian for a given cycle, nothing is returned. The first NULL value in a cycle is returned even if the cycle contains more NULL values.
Integral Retrieval
Integral retrieval calculates the values at retrieval cycle boundaries by integrating the graph described by the points stored for the tag. Therefore, it works much like average retrieval, but it additionally applies a scaling factor. This retrieval mode is useful for calculating volume for a particular tag.
Slope Retrieval
Slope retrieval returns the slope of a line drawn through a given point and the point immediately before it, thus expressing the rate at which values change. The first NULL following a non-NULL value is returned. Subsequent NULL values are not returned.
two points P1 and P2 occurring at times T1 and T2, the slope formula is as follows: (P2 - P1) / (T2 - T1)
The difference between T1 and T2 is measured in seconds. Therefore, the returned value represents the change in Engineering Units per second.
Counter retrieval
Counter retrieval allows you to accurately retrieve the delta change of a tag’s value over a period of time even for tags that are reset upon reaching a rollover value. The rollover value is defined in Historian for each tag.
This retrieval mode is useful for determining how much of an item was produced during a particular time period. For example, you might have an integer counter that keeps track of how many cartons were produced. The counter has an indicator like this:

ValueState retrieval
ValueState retrieval returns information on how long a tag has been in a particular value state during each retrieval cycle. That is, a time-in-state calculation is applied to the tag value.
This retrieval mode is useful for determining how long a machine has been running or stopped, how much time a process spent in a particular state, how long a valve has been open or closed, and so on. ValueState retrieval can return the shortest, longest, average, or total time a tag spent in a state, or the time spent in a state as a percentage of the total cycle length.
Minimum – Shortest amount of time that the tag has been in each unique state
Maximum – Longest amount of time that the tag has been in each unique state
Average – Average amount of time that the tag has been in each unique state
Total – Total amount of time that the tag has been in each unique state
Percent – Total percentage of time that the tag has been in each unique state
MinContained – Shortest amount of time each tag has been in each unique state for each cycle, disregarding the occurrences that are not fully contained with the calculation cycle
MaxContained – Longest amount of time that the tag has been in each unique state for each cycle, disregarding the occurrences that are not fully contained with the calculation cycle
AvgContained – Average amount of time that the tag has been in each unique state for each cycle, disregarding the occurrences that are not fully contained with the calculation cycle
TotalContained – Total amount of time that the tag has been in each unique state for each cycle, disregarding the occurrences that are not fully contained with the calculation cycle
PercentContained – Percentage of time that the tag has been in each unique state for each cycle, disregarding the occurrences that are not fully contained with the calculation cycle
RoundTrip retrieval
RoundTrip retrievaluses the time between consecutive leading edges of the same state for its calculations.
You can use the RoundTrip retrieval mode for increasing the efficiency of a process. For example, if a process produces one item per cycle, then you would want to minimize the time lapse between two consecutive cycles.
For RoundTrip retrieval, you can only specify the following types of state calculations (aggregations) to be performed on the data. The calculations are for each unique state within each retrieval cycle for the query.
MinContained – Shortest time span between consecutive leading edges of any state that occurs multiple times within the cycle, while disregarding state occurrences that are not fully contained inside of the cycle
MaxContained – Longest time span between consecutive leading edges of any state that occurs multiple times within the cycle, while disregarding state occurrences that are not fully contained inside of the cycle
AvgContained – Average time span between consecutive leading edges of any state that occurs multiple times within the cycle, while disregarding state occurrences that are not fully contained inside of the cycle (This is the default.)
TotalContained – Total time span between consecutive leading edges of any state that occurs multiple times within the cycle, while disregarding state occurrences that are not fully contained inside of the cycle
PercentContained – Percentage of the cycle time spent in time span between consecutive leading edges for a state that occurs multiple times within the cycle, while disregarding value occurrences that are not fully contained inside of the cycle